
This is a dataset paper from ICWSM 2020, presenting a dataset of nearly 80,000 news stories focusing on the 2020 US Presidential Election throughout 2019. It was shared to help researchers studying agenda setting and algorithmic curation of news.
Authors: Anna Kawakami, Khonzodakhon Umarova, Eni Mustafaraj (Wellesley College)
Link: ICWSM proceedings or video
Background and motivation
Yesterday, I read a paper on an algorithmic audit of Apple News, so today I decided to read about a related dataset from ICWSM 2020. Google’s news system is different: it shows some “top stories” at the top of relevant search queries.
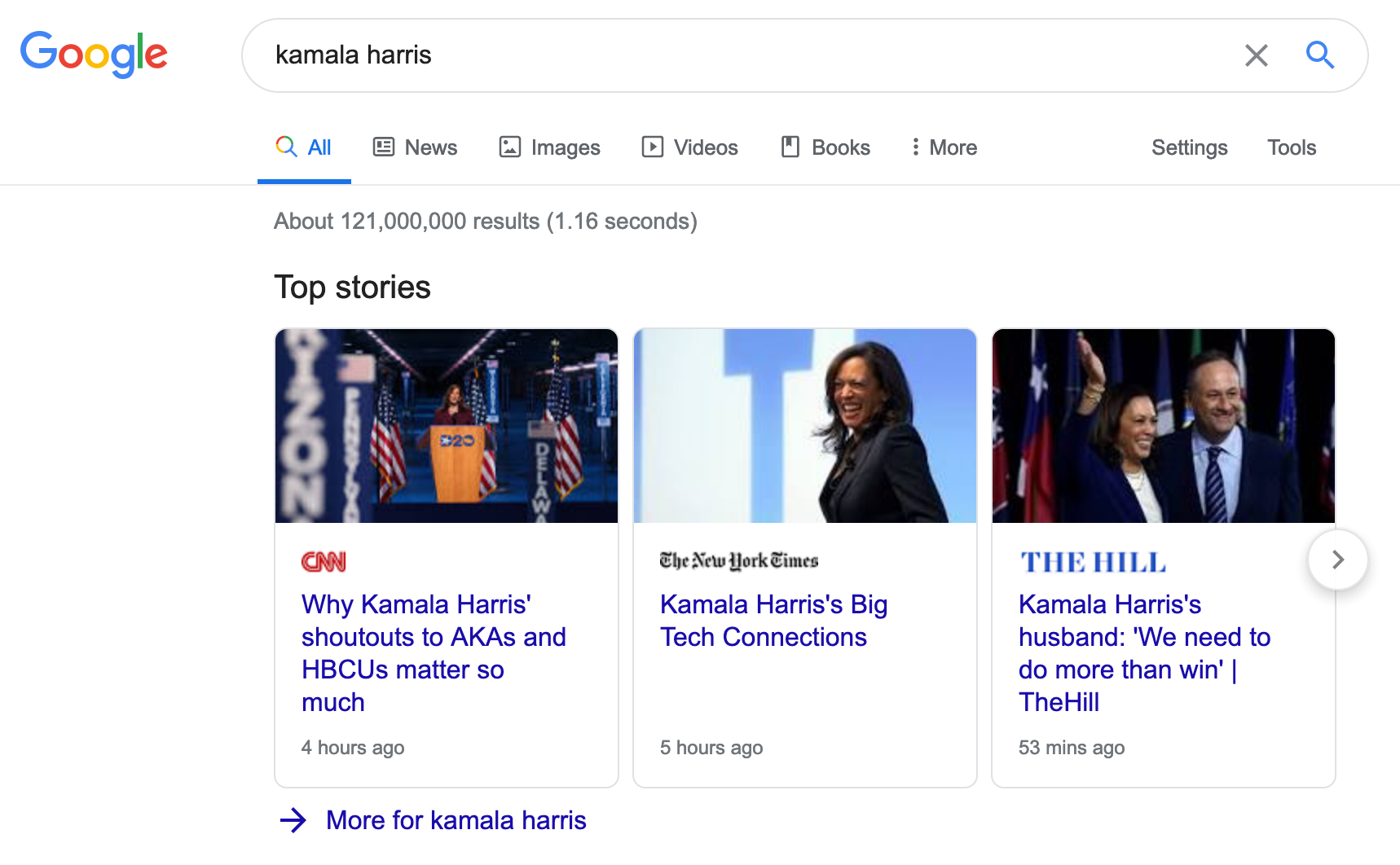
The authors collected data with the goal of enabling researchers to study algorithmic curation of news, just as Brandy & Diakopoulos did in yesterday’s paper.
Dataset
The dataset contains:
- an entire year of search results for 30 political candidates in the 2020 US elections
- between 4 and 12 daily measurements of the top stories
They tested other questions:
- location: replicated data collection from another location, 1000 miles away, and found that it did not affect Top Stories
- query formulation: this dataset used first and last name, but (for some candidates, e.g., Kamala Harris) there were different results when searching just the last name.
- device type: they used a laptop here, considering mobile to be out of scope but interesting for the future.
Analysis
This is the first “dataset paper” I’ve read, and while I thought the primary contribution was the dataset, the authors also answered some questions about it.
Which news sources does top stories prefer? While there were 2,168 news sources, a third of all articles were produced by just 8 sources. That’s a similar finding to the source centralization mentioned in yesterday’s work.
Is there partisan bias? Not really. When matching the URL sources to the Partisan Audience Bias dataset (which measured how often left- and right-leaning Twitter users shared a given link), the histogram of “bias scores” is symmetric.
There were 2,168 news sources, but a third of all articles were produced by just 8 publishers. (The coverage of the candidates varied as well.)
Which presidential candidates do news sources prefer? The “upper tier” (i.e., 8 most frequent) sources account for 40% of Trump and Biden’s coverage (remember that this was in 2019!), 33% of Warren and Sanders’, and 25% of many others (Gabbard, Booker, etc.). Bloomberg focused on Michael Bloomberg (surprise!), and for some reason Breitbart was focused almost exclusively on Joe Biden.
How sticky are the top sources? That is, how often are stories replaced? The primary frontrunners (i.e., Biden, Warren, Sanders, and Buttigeg) were the least sticky, meaning new stories about them appeared frequently. Articles about less popular candidates were more likely to stay for longer.
Future research questions
Agenda setting: for the 2020 elections, on what aspects of the candidates’ campaigns is (or was, last year) the media focusing? Are they talking about “electability” of women candidates, or their platforms?
Balanced inclusion of partisan stories: is Google trying to present stories from across the political spectrum? (Granted, I don’t think they should be—given that there was only a Democratic primary race, who cares if Fox News shows up?)
Closing thoughts
Cool! I don’t think I’ll ever return to this dataset, if I’m being honest. But it’s a valuable contribution nonetheless, and I would love to read about future work that makes use of this data.